What is Configuration anyway? And why is it so hard?


CUE Labs is a configuration company. CUE is a configuration language. Our Configuration Control Plane is an end-to-end solution for everything configuration management. That raises a basic question: what do we actually mean by “configuration”?
Let’s start with a simple, real-world example: a washing machine. You need to wash your favorite cashmere sweater ahead of the weekend (the intent). Before you press “start”, you must actively turn the dials to select a temperature, cycle, and spin speed. This act of choosing is configuration (the process). Once you stop turning the dials, the specific combination you settled on, for example (and perhaps disastrously) “90°C, Cotton, 1200rpm”, is the configuration (the specification). The machine uses this specification to know how to run. Let’s see how this turns out (the outcome)!
In an ideal world, this sequence is seamless. You start with a clear intent, follow the process, and create a specification. The machine executes it, and the outcome is exactly what you wanted: there is no gap between expectation and reality:
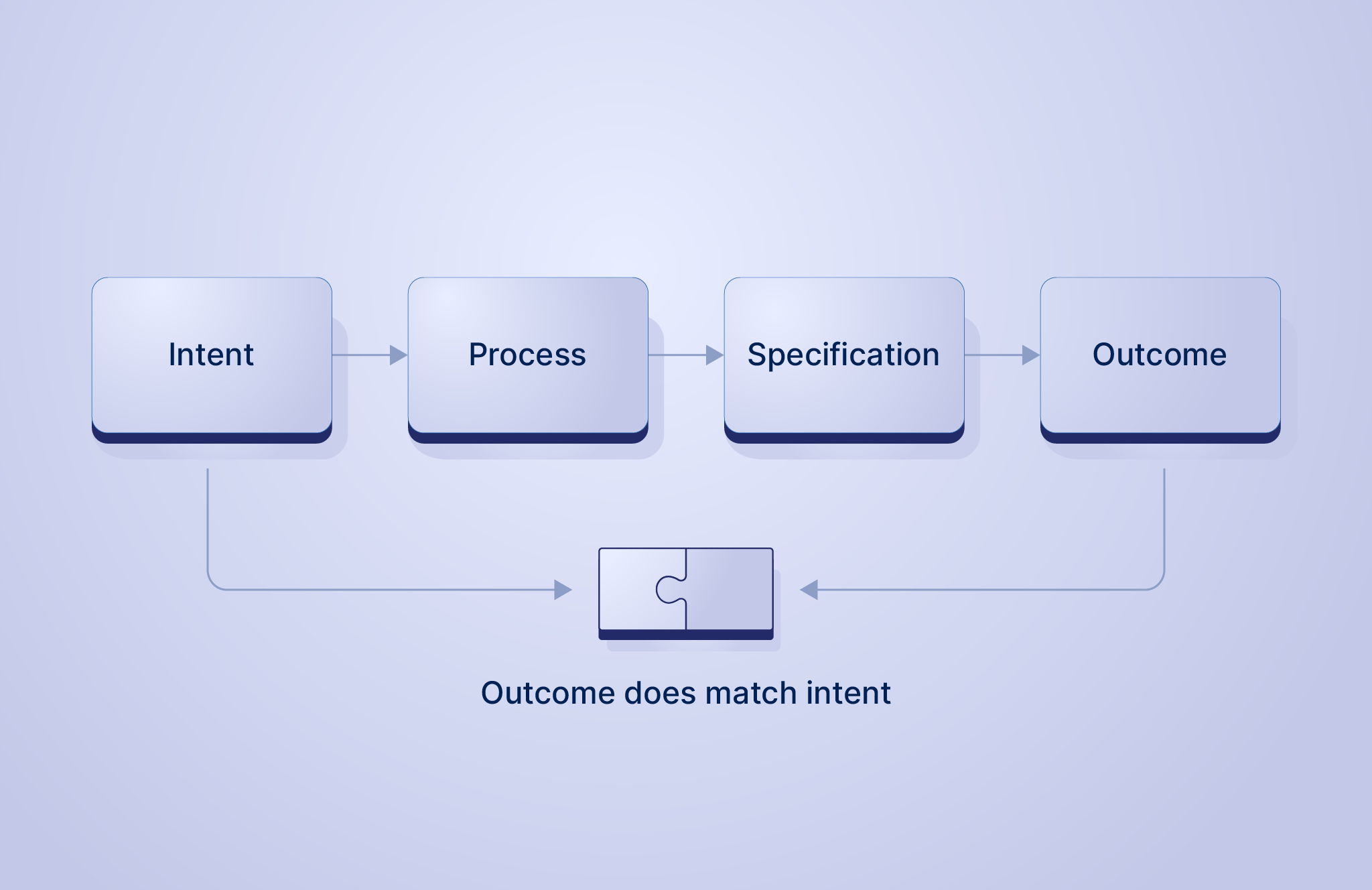
Configuration is Everywhere
Once you see the analogy of the washing machine, you realize that configuration is a universal concept. Almost all systems require configuration (a specification) to operate, and as a result, we are all “doing configuration” (the process) the whole time.
Consider the following examples:
- A washing machine: Choosing the temperature, cycle, and spin speed appropriate for the garments.
- A Wi-Fi router: Naming the network and setting the password, configuring access controls, and maintaining blocked device lists.
- A CNC milling machine: Engineers calculate tool paths, speeds, and materials so the same machine can produce completely different metal components.
- A hospital MRI scanner: Technicians configure scan sequences, contrast liquid timings, and field strength based on the specific body part being scanned.
- A cloud service: DevOps engineers configure ports, permissions, and scaling rules to define how a massive software application behaves in production.
What varies considerably between these situations is the cost of failure when things go wrong.
Configuration is not so simple
We think of things “going wrong” when there is a gap between how we intended the system to behave and how it actually behaved.
Sometimes, this gap occurs because the system fails to execute the specification. If the washing machine motor burns out mid-cycle, that is a hardware failure; the machine physically couldn’t do what it was told.
However, when we talk about “bad configuration”, we are looking at situations where the machine works exactly as designed. It followed the specification perfectly, yet the outcome still failed to match our intent. The failure wasn’t in the mechanism; it was in the instruction we gave it. We call these configuration-related errors.
Returning to our washing machine: The intent was to clean the sweater. The reality is a shrunken garment that fits a toddler.
On further analysis, we discover the cause was the “90°C” setting. But how did we arrive at that setting? Perhaps we didn’t check the label (process skipped). Perhaps the label was missing (unknown constraint). Or perhaps we just guessed.
Whatever the answer, the causality is clear: A “bad configuration” process led to a “bad configuration” specification, which led to the failure, the gap between how we intended the system to behave and how it actually behaved.
The stakes for configuration-related errors range from a minor inconvenience (a shrunken sweater) to significant financial loss (a cloud service outage) or even serious injury.
This sounds straightforward. So, if configuration errors cost billions, why haven’t we simply designed a bullet-proof process to prevent them?
It turns out that unlike the washing machine, which is a simple solo activity, configuring the internet is a complex team sport. And that makes it a really hard problem.
Many hands make more work
We have established the causal link: Bad Process -> Bad Specification -> Failure/Error/Outage.
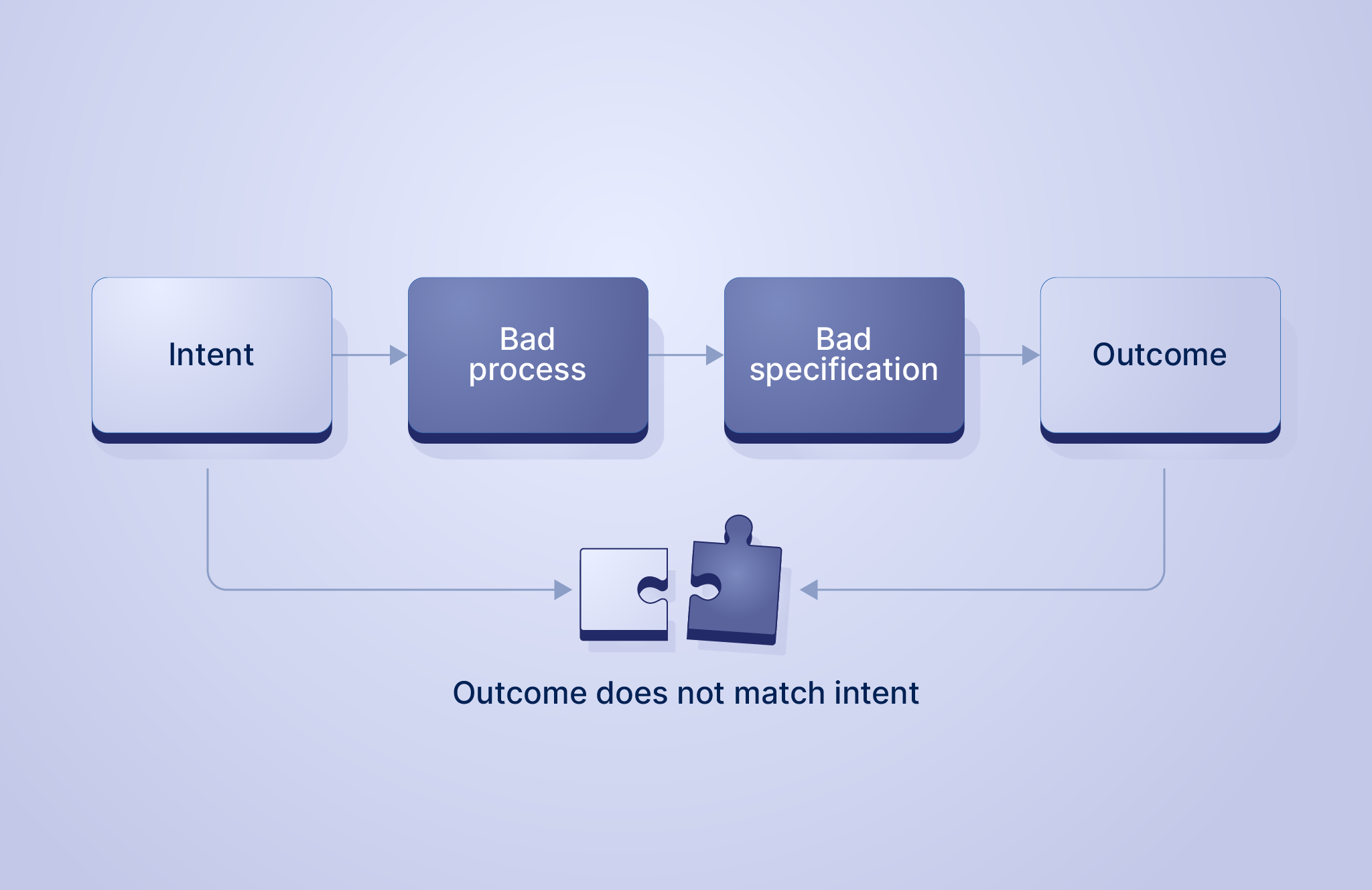
To reduce the outages, we must fix the process. A “good configuration” process acts as a filter. It catches problems early, preventing the bad specification from ever existing. In DevOps lingo, we call this shifting left.
In our washing machine analogy, the process is simple: one person (you), one system (the machine). The chance of error is low because you own the entire loop.
But in modern infrastructure, the process is more complex. We have multiple people responsible for multiple systems, all connected by invisible dependencies, sometimes with long delays before we see something has gone wrong. Furthermore, the addition of every new person or system introduces combinatorial complexity.
In these environments, configuration is no longer just “choosing settings”; it is the act of achieving consensus among potentially competing interests. Mapping this complexity back to our washing machine analogy:
- The Developer specifies the values (Cycle Temperature).
- The SRE captures expert knowledge as rules (“No high spin on delicate cycles”).
- The Security Team sets the policy (“Machine must only run at night”).
These individuals are all actors, and each needs their constraints to hold true for things to be “good”. The problem is that the process of reliably and repeatedly achieving this consensus is itself complex.
It is this complexity that overwhelms configuration, turning a manageable task into a source of failure. Informally, we can model this compounding difficulty as:
$$\text{Actors} \times \text{Systems} \times \text{Connections} \times \text{Feedback Latency} = \text{Complexity}$$
Therefore to reduce the outages, we need to manage the complexity of the configuration process and the way it scales.
Why Traditional Processes Fail
The problem is that today, we lack the tools to manage this complexity. We cannot simply “do the math” to see if the constraints align.
Instead, we rely on humans to “coordinate,” to “remember” hidden dependencies, and to “patch over” the conflicts with manual review.
If humans are on the critical path, we will make mistakes. When the process is painful or high-friction, we take shortcuts. And as we begin to add AI Agents as actors in this process, the complexity and rate of change will only increase.
Whether the actors are human or digital, the lack of adequate tooling exacerbates this inherent complexity. Instead of managing the variables in our equation, our current processes turn them into universal friction points:
- Broken Connections: We lack the ability to link related settings, forcing us to rely on human memory to manually update one part of the system when another part changes.
- Siloed Expert Knowledge: We lack the ability to encode rules directly, forcing us to rely on word-of-mouth or manuals to ensure settings make logical sense, rather than the system preventing the mistake.
- High Feedback Latency: We lack the ability to validate our work immediately, forcing us into a slow trial-and-error process where we only discover errors long after we’ve finished the task.
- Rigid Actor Boundaries: We lack the ability to share control safely, forcing us into “gatekeeping” workflows where only one person can “hold the pen,” requiring meetings just to negotiate a change.
- Unscalable Systems: We lack the ability to safely reuse best practices, forcing us to “copy-paste” old configurations and creating a mess of code drift that makes adding new systems a nightmare.
- Untrusted Constraints: We lack the ability to guarantee safety rules are respected, meaning we cannot trust other actors to work independently without accidentally breaking our requirements.
Collectively, these friction points create a coordination tax that grows exponentially, making it more difficult to manage complexity.
This is why traditional configuration doesn’t scale.
In the end, the concept of configuration is simple: translating intent into a specification that gives you the outcome you wanted. The hard part? Managing real-life complexity in the configuration process.
To solve this, we need tools that scale with the problem. We need a system that handles the complexity of validation and composition, allowing us to add more actors (human or AI) without adding more chaos.
In the next blog post, we will start to explore how CUE and the Configuration Control Plane significantly reduce complexity, filtering errors as early as possible (shifting left) to prevent costly outages and configuration-related errors, giving you an easy and scalable way to translate your intent into a specification that works.


